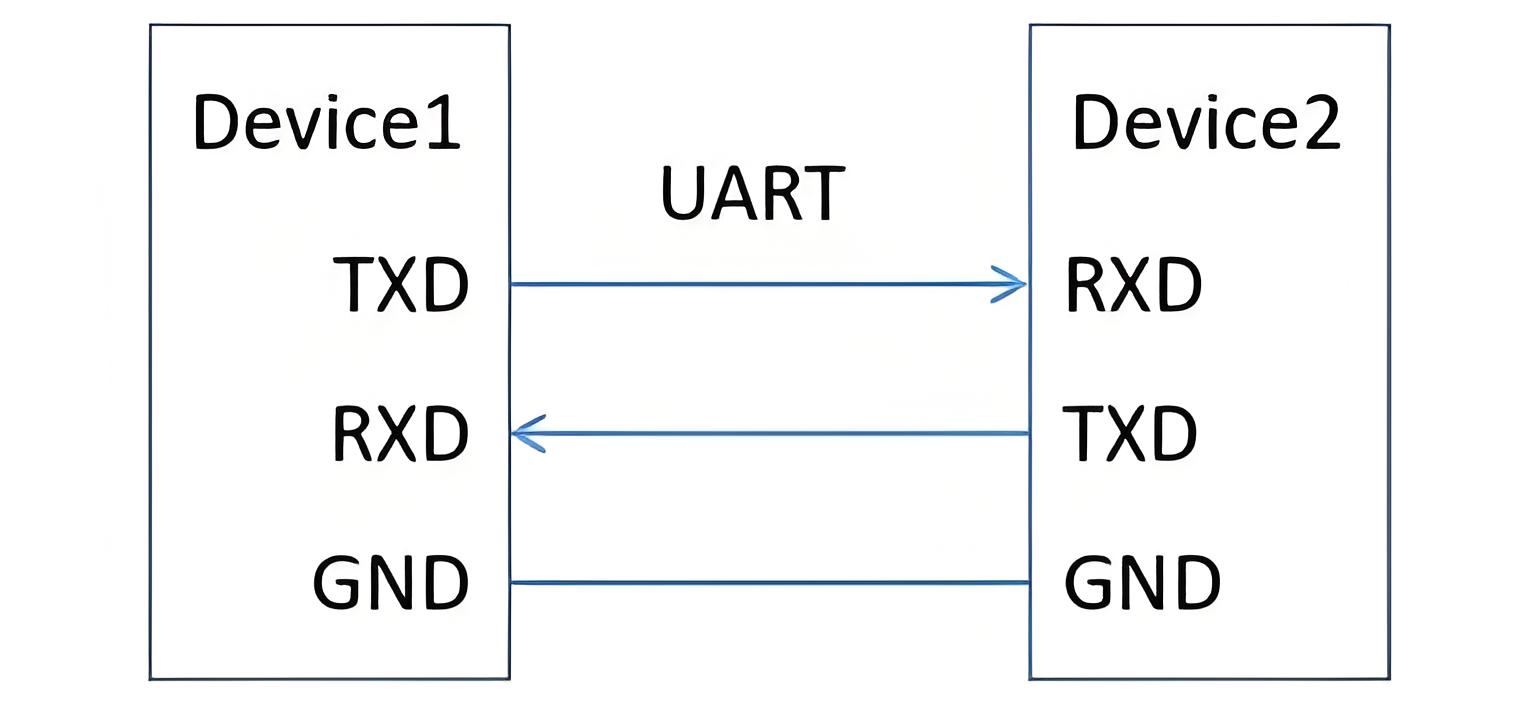
本文最后更新于2 天前,其中的信息可能已经过时,如有错误请发送邮件到big_fw@foxmail.com
2025年是中国AI大模型发展的关键之年。从DeepSeek-R1的开源突破到各大厂商的激烈竞争,中国AI产业正在经历前所未有的变革。本文将梳理2025年中国大模型领域的重要进展。
一、DeepSeek-R1:开源模型的里程碑
2025年1月,深度求索发布开源推理模型DeepSeek R1,性能比肩OpenAI o1,但训练成本仅约560万美元。这一突破性进展迅速引发全球关注:
- 模型登顶全球应用商店榜首
- 引发美股震荡,英伟达市值一度蒸发近6000亿美元
- 美国硅谷风险投资者马克·安德里森称其为「AI领域的Sputnik时刻」
- 彻底打破算力至上的传统范式
二、阿里云通义千问的持续进化
阿里云在2025年持续发力:
Qwen2.5-Max(1月发布)
- MoE架构的最新成果
- 预训练数据超过20万亿tokens
- 全面超越当时全球领先的开源MoE模型
Qwen2.5-VL(1月28日)
- 全新的视觉模型
- 推出3B、7B和72B三个尺寸版本
- 突破性支持超1小时的视频理解
Qwen3系列(4月发布)
- 一次性推出8款开源模型
- 涵盖多种参数规模
- Hugging Face下载量持续领先
三、百度的开源转型
3月16日,百度发布文心大模型4.5和X1并免费开放:
- 文心4.5:新一代原生多模态基础大模型,多模态能力优于GPT-4o,API价格仅为竞品1%
- 文心X1:首个自主运用工具的深度思考模型,可调用搜索、绘图、代码等多款工具
- 6月30日,百度正式开源文心4.5系列共10款模型,标志着从闭源走向开源的重大转变
四、其他重要进展
华为盘古Ultra MoE(5月30日)
- 参数规模高达7180亿
- 全流程在昇腾AI计算平台上训练
- 实现从硬件到软件的全栈国产化闭环
字节跳动豆包大模型
- 6月发布1.6版本,日均Token使用量较去年增长137倍
- 12月发布1.8版本,日均tokens调用量超过50万亿
- 在中国公有云大模型API市场份额达46.4%,位居第一
月之暗面Kimi K2
- 7月发布万亿参数规模的K2模型
- 11月发布K2 Thinking深度思考版本
- 12月完成5亿美元C轮融资,现金储备达100亿人民币
五、行业趋势与展望
2025年的中国大模型市场呈现以下特点:
- 开源成为主流:从DeepSeek到阿里、百度,开源策略成为竞争关键
- 多模态能力标配:视觉、视频理解成为大模型的标准配置
- 成本持续下降:训练成本和API价格大幅降低
- 应用场景爆发:从对话走向Agent,工具调用能力增强
- 国产算力崛起:华为昇腾等国产芯片支撑大模型训练
结语
2025年中国AI大模型的发展表明,技术创新和开源生态正在重塑全球AI格局。随着模型能力的不断提升和成本的持续下降,AI技术将在更多领域实现落地应用,为各行各业带来深远变革。
本文整理自公开资料,仅供参考学习。